

「RVC(Retrieval-based-Voice-Conversion)」で好きなキャラで歌わせよう!
RVC(Retrieval-based-Voice-Conversion)とは?
皆さんRVC(Retrieval-based-Voice-Conversion)知っているでしょうか?
現在様々なAIを活用したサービスがあります。
テキスト生成をしてくれる「ChatGPT」「GoogleBird」など、画像生成AI「Midjourney」などAIを活用したサービスが様々あります。
RVC(Retrieval-based-Voice-Conversion)とは自分の声を機械学習させた声に変換してくれるAIソフトウェアの1つですです。
今回はこのRVCを利用して好きなキャラに歌わせていきたいと思います。
※RVC(Retrieval-based-Voice-Conversion)を省略させてもらいます。
事前準備
ソフトのインストール
まず声を学習するためにはRVCのソフトと学習させたい声を準備する必要があります。
今回は学習させてい声をずんだもんとして解説させていただきます。
まず声を学習するために必要なソフトRVCをダウンロードしていこうと思います。
以下のURLをクリックしてください。
「https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases」
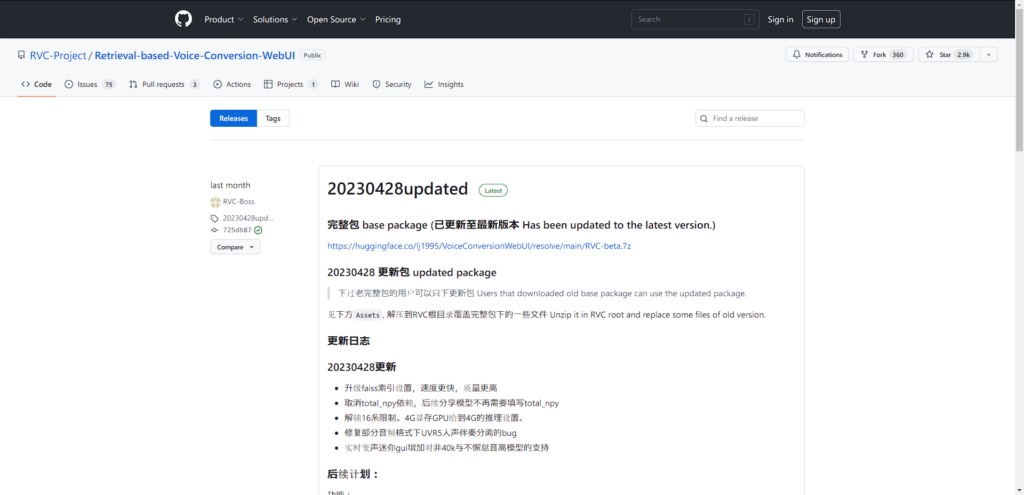
リンクをクリックしたら以下のような画面が出てくると思います、こちらのページを下にスクロールしてもらうと「完整包 base package (已更新至最新版本 Has been updated to the latest version.)」という文があると思います。

こちらの文の下のURLをクリックしてもらうとダウンロードが開始されます。
ちなみにソフトのバージョンがアップデートされた場合上記の「○○○○○○update」の〇〇〇〇がアップデートした日数になっていると思うので、もし「○○○○○○update」の数値が違っても同じ手順でダウンロードしてもらえると最新版がダウンロードされると思います。
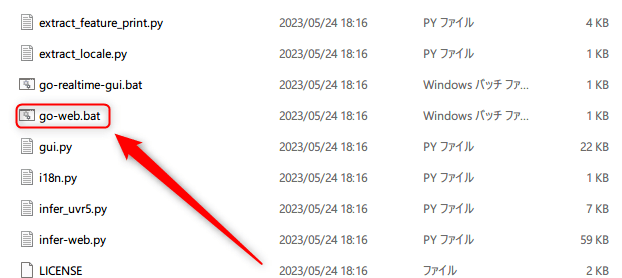
ダウンロードしたファイルを解凍してもらうとフォルダの中に「go-web.bat」という実行ファイルがあると思います。
こちらをダブルクリックしてくださいそうすることで、以下の画面が現れた後
ここに画像春
このような画面が現れると思うのでそのまま「はい」を押してください
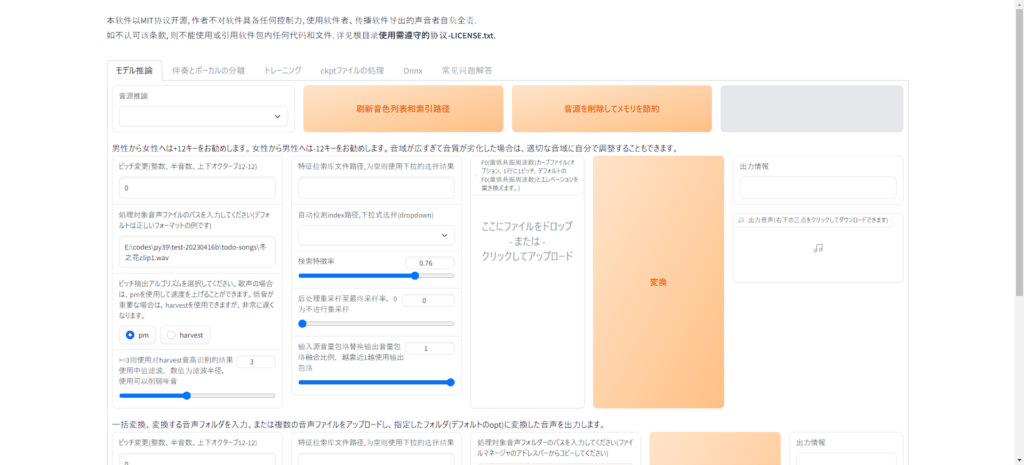
押したらウェブブラウザが立ち上がりこのような画面が出てきます、これでソフトのインストールは完了です。
また実行したいときは「go-web.bat」を押したら実行されます
学習音声のダウンロード
今回は学習先の音声を既存の配布されている音声を使いたいと思います。
個々の音声を変えることで自分の好きなキャラに歌わせることができます。
今回は学習先の音声を既存の配布されている音声を使いたいと思います。
個々の音声を変えることで自分の好きなキャラに歌わせることができます。
今回はSSS合同会社様が提供している「研究者向け マルチモーダルデータベース」から素材をダウンロードしていこうと思います。
声を学習するために必要なボイスをダウンロードしていこうと思います。
以下のURLをクリックしてください。
「https://zunko.jp/multimodal_dev/login.php」
©SSS
リンクをクリックしたら以下のような画面が出てくると思います、こちらのページを下にスクロールしてもらうと「規約に同意し、twitterでログインする」というボタンがあるのでボタンをクリックしてログインしてください。
©SSS
ログインこのような画面が出てくると思うので、規約を読んでもらって、下にスクロールしてもらうとたくさんのキャラクター「ずんだもん、東北イタコ、四国メタン、九州ソラ」様などの様々なキャラクターがいると思うのですが今回はずんだもんに機械学習先の音声になってもらいます。
©SSS
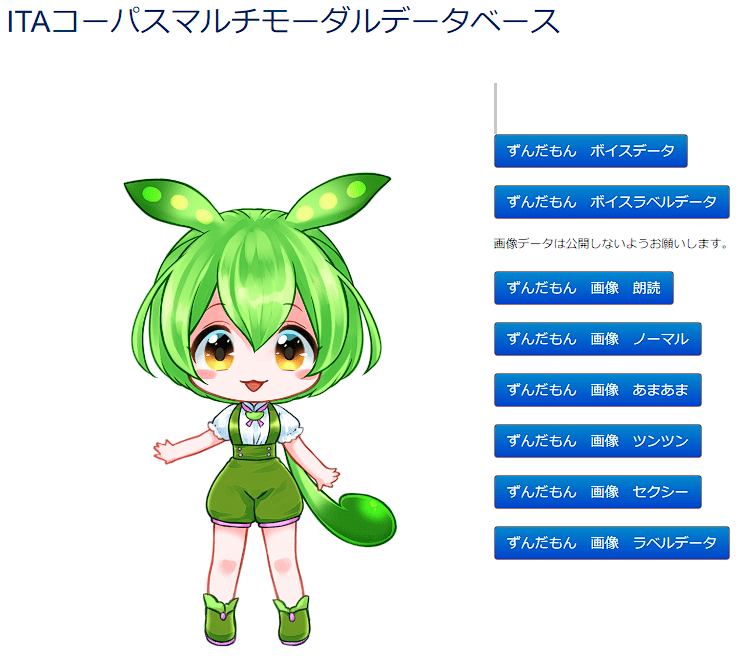
下にスクロールしてもらうとキャラクターに各種ダウンロードボタンがあると思うので
「ダウンロードしたいキャラクター+ボイスデータ」をダウンロードしていきたいと思います。
今回はずんだもんなので「ずんだもん ボイスデータ」をクリックしてダウンロードしてください。

ダウンロードしてもらうとこのようなファイルがあると思いますので解凍してください。
解凍したらこのようなファイルがあると思うので「emotion」を開いて

開いたらこのようなファイルがあるので「normal」をクリックしてください。
「normal」をクリックしていただけるのこのようにたくさんの学習用音声が入ってるファイルがあると思います。
今回はこちらの音声を学習させていただきます。
まずこちらのファイルのパスを取得します。
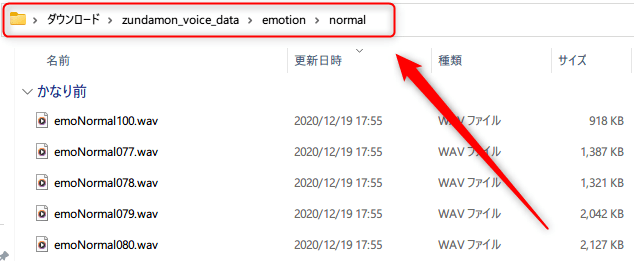
こちらの赤枠のところをダブルクリックするとダブルクリックしたところが青くなると思うのでそれをコピーしてください
ちなみに自分の場合のパスはこんな感じです
「C:\Users\自分のユーザー名\Downloads\zundamon_voice_data\emotion」
コピーし終えたら次はいざ学習作業です!
学習作業
まず先ほど実行したRCVの画面を開いてください。
↓こちらの画面です
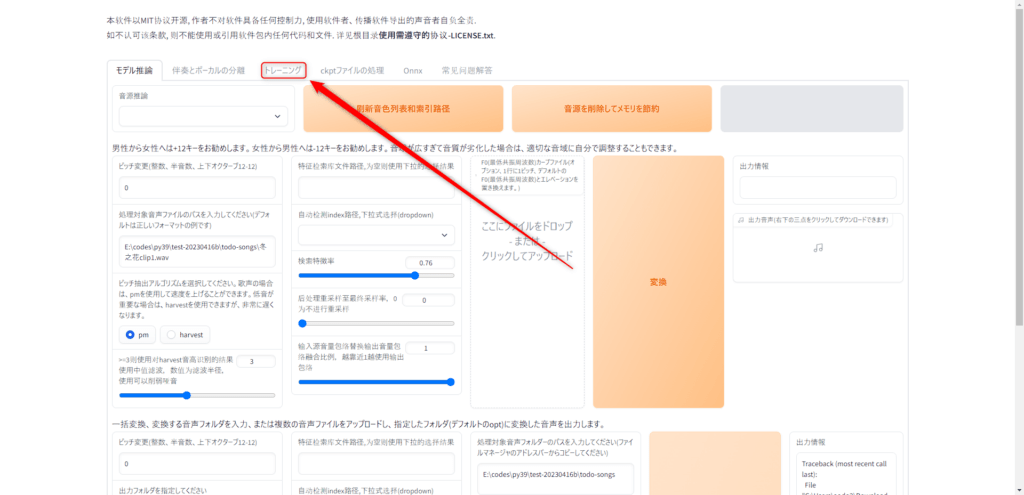
上のバーから「トレーニング」クリックしください。
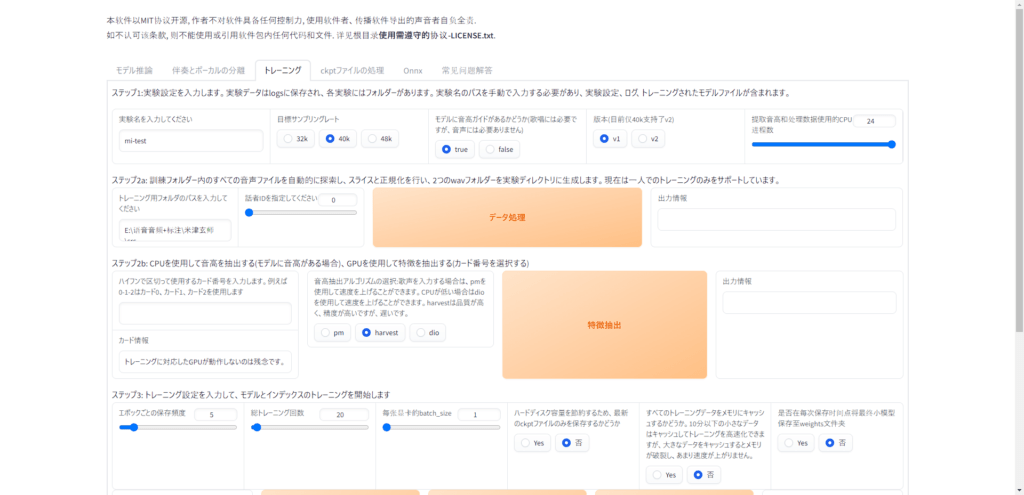
「トレーニング」をクリックするとこのような画面があります。この画面で音声を学習していきます。
ステップ1

まず「実験名を入力してください」という欄があります、こちらはこのソフトで表示される名前を指定します、なので今回はずんだもんなので「Zundamon」と入力します(ここはなんでも可)
次に「目標サンプリングレート」という欄にに「32k,40k,48k」とありますこちらは特に理由がない場合は初期値の40kで大丈夫です。
次に「モデルに音高ガイドがあるかどうか(歌唱には必要ですが、音声には必要ありません)」という欄がありますが、今回は歌を歌ってもらうので初期値の「true」で大丈夫です。
次に「版本(目前仅40k支持了v2)」こちらはバージョンの設定です現在「v1,v2」がありますが、v2をサポートしているのは、2つ前に説明した「目標サンプリング」の「40k」のみサポートしています
今回は40kに設定しているので「v2」のボタンをクリックしてください
次に「提取音高和处理数据使用的CPU进程数」という項目ですがこちらは処理に使われるCPUプロセスの量を設定します、初期値では実行しているパソコンの最大プロセスが割り当てられているので特に問題がない方はそのままの数値で大丈夫です。
ステップ2a

次に「トレーニング用フォルダのパスを入力してください」という欄があるので先ほどコピーしておいたパスをペーストしてください。
例「C:\Users\自分のユーザー名\Downloads\zundamon_voice_data\emotion」
次に「話者IDを指定してください」とあるのですがこれは初期値のままで大丈夫です。
次に真ん中に大きく「データ処理」というオレンジ色のボタンがあるのでクリックしてください、そしたら「出力情報のところに色々文が出てくると思います。
「出力情報の画面が下記のように「end preprocess」と出たらステップ2aは完了です。

ステップ2b

次に処理を行うときにGPUの選択をします
GPUがないまたは対応していない場合
GPUがないまたは対応していないときは上記のように「カード情報」と「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」となっているところが空になっています。その場合は次の工程を無視してください。
GPUが1枚の場合

GPUが対応している場合「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」と「カード情報」の場所に「0」 「0 認識しているGPUの名前」となっているはずです。
この画面ではどのGPUを使うかの設定をします
「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」のところに使うGPUの番号が入力されていると思います。
今回の場合はGPUが一枚でGPUナンバーが0番なので「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」のところに「0」と書かれています
この場合初期値が入力されているので次の工程に行って大丈夫です。
GPUが複数枚の場合
こちらに関しては画像がないので合っているかわかりませんが「カード情報」のところに例
「0 NVIDIA GeForce GTX 1070 : 1 NVIDIA GeForce GTX 1060」みたいになっていると思います
「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」の場所が「0」のみになっている場合0番のGPUが使用されます。逆に0番と1番のGPUを使用する場合は「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」の場所に「0-1」のように記述していただければ大丈夫です。
次に「音高抽出アルゴリズムの選択:歌声を入力する場合は、pmを使用して速度を上げることができます。CPUが低い場合はdioを使用して速度を上げることができます。harvestは品質が高く、精度が高いですが、遅いです。」の欄ですがボタンが3つあり「pm,harvest,dio」の三種類があります。
まずpmは歌声の場合はこちらを選びますこちらは音高抽出アルゴリズムの速度がharvestよりも早いです。
次にharvestこちらは歌声以外(会話)などに使用します、こちらはdioやpmよりも速度が遅いですが品質と精度がよいです。
今回は歌を歌ってもらうので「pm」を選択します。
選択し終えたら真ん中に大きく「特徴抽出」というオレンジ色のボタンがあるのでクリックしてください、そしたら「出力情報のところに色々文が出てくると思います。
「出力情報の画面が下記のように「all-feature-done」と出たらステップ2bは完了です。

ステップ3
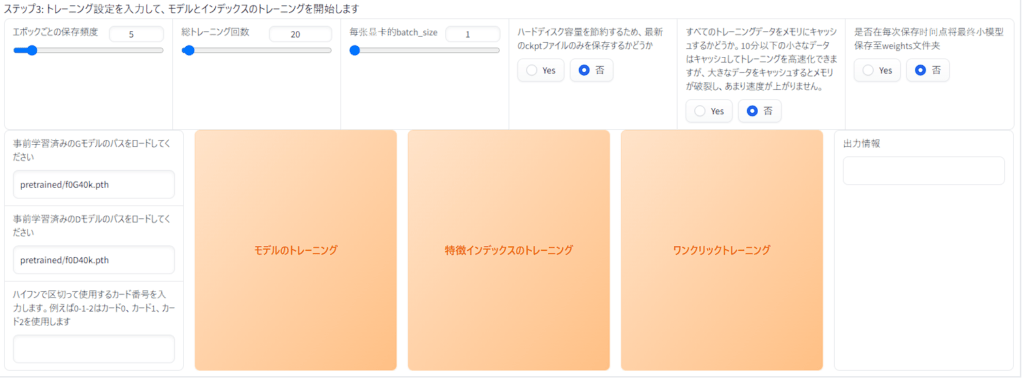
ここまで来たら学習作業はあとわずか、後少しで休憩時間が来るので頑張りましょう!
まず「エポックごとの保存頻度」の数値は学習中は時間がかかるので何分経ったら保存するかの保存頻度ですこれは初期値の「5」分で大丈夫です。好きな数値にしてください
次に「総トレーニング回数」ですこちらは数値が大きいほど声の安定感など音質などがよくなります
この数値を大きくするほど学習時間がかかるので最初は練習がてら初期値の「20」で大丈夫だと思います。
ちなみに総トレーニング回数を100回ぐらいにすると3時間ほどかかりました(多分低スぺだから)。
次に「每张显卡的batch_size」こちらはメモリの量を設定しています数値を大きくするほど学習が早くなりますが大きくしすぎるとメモリ不足で学習が止まってしまうので気を付けてください!!
次に「ハードディスク容量を節約するため、最新のckptファイルのみを保存するかどうか」こちらは特に理由がなければ「否」でokです。
次に「すべてのトレーニングデータをメモリにキャッシュするかどうか。10分以下の小さなデータはキャッシュしてトレーニングを高速化できますが、大きなデータをキャッシュするとメモリが破裂し、あまり速度が上がりません。」これも特に理由がなければ「否」でokです。
次に「是否在每次保存时间点将最终小模型保存至weights文件夹」これは日本語にすると「各保存時点で最終的な小型モデルを重みフォルダーに保存するかどうか」になります、これも特に理由がなければ「否」でokです。
次に下側にある「事前学習済みのGモデルのパスをロードしてください」と「事前学習済みのDモデルのパスをロードしてください」これも特に理由がなければそのままでokです。
次に「ハイフンで区切って使用するカード番号を入力します。例えば0-1-2はカード0、カード1、カード2を使用します」これはステップ2bで解説したGPU番号が割り当てられていると思います。
これで学習作業で入力することは終わりました、お疲れ様です。
最後に下側の右にある「ワンクリックトレーニング」を押してください、これで学習作業が始まります、学習作業は時間がかかるのでしばし休憩をしましょう!
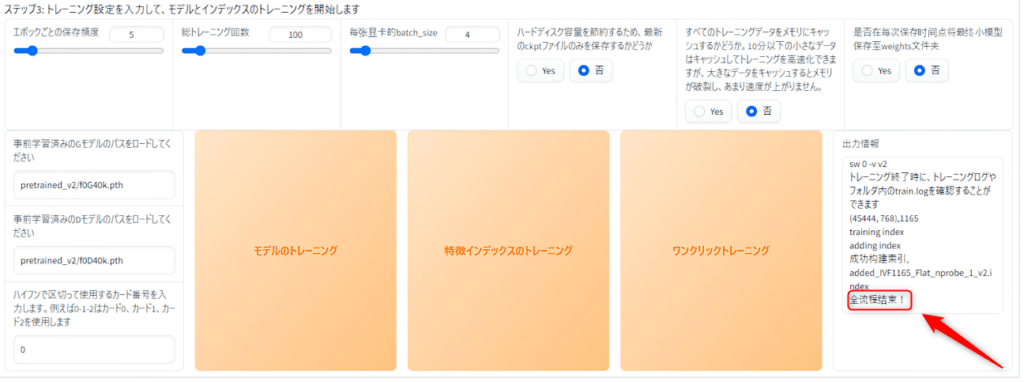
学習作業が終わると「出力情報」のところに「全流程结束!」と出てくると思います。
これで学習作業は終わりました。
歌わせるための事前準備
次に歌わせるための音源を用意します
今回はフリー音源のこちら↓魔王魂様のシャイニングスターという楽曲を利用させて頂きます。
「https://maou.audio/14_shining_star/」
自分で用意した音源を利用する場合はこちらの工程を飛ばし「音楽から声とそれ以外の抜き出し」に進んでください。
音源のダウンロード
先ほどのリンクをクリックしてもらうと下記のようなサイトに飛ぶと思うので、こちらから「ダウンロード」ボタンを押してください。
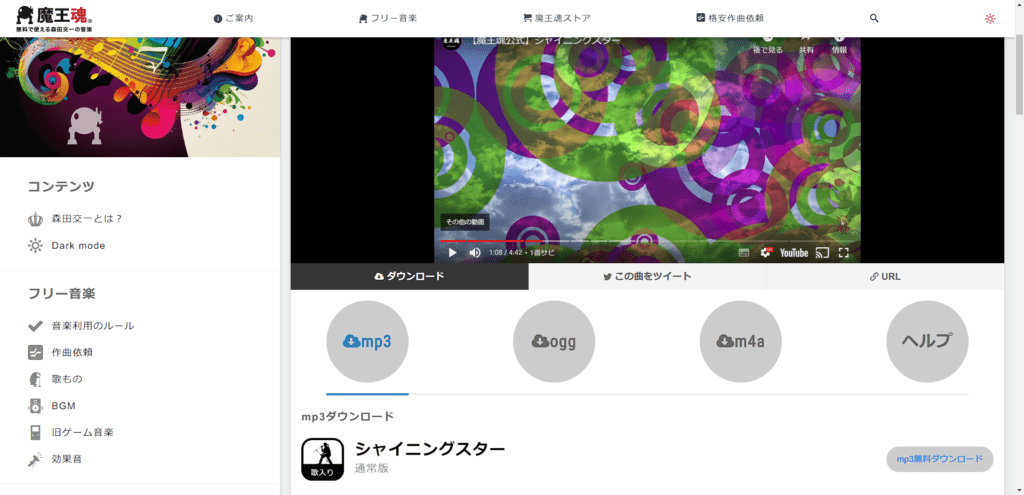
押すとこのように「mp3,ogg,m4a」など選ぶ場所が出ますがmp3で大丈夫です。
下側の「mp3無料ダウンロード」を押してもらうとダウンロードが開始されます。

このようなファイルができていると思います。
音楽から声とそれ以外の抜き出し
まず先ほど実行したRCVの画面を開いてください。
開いたら上バーから「推論伴奏とボーカルの分離」をクリックしてください。
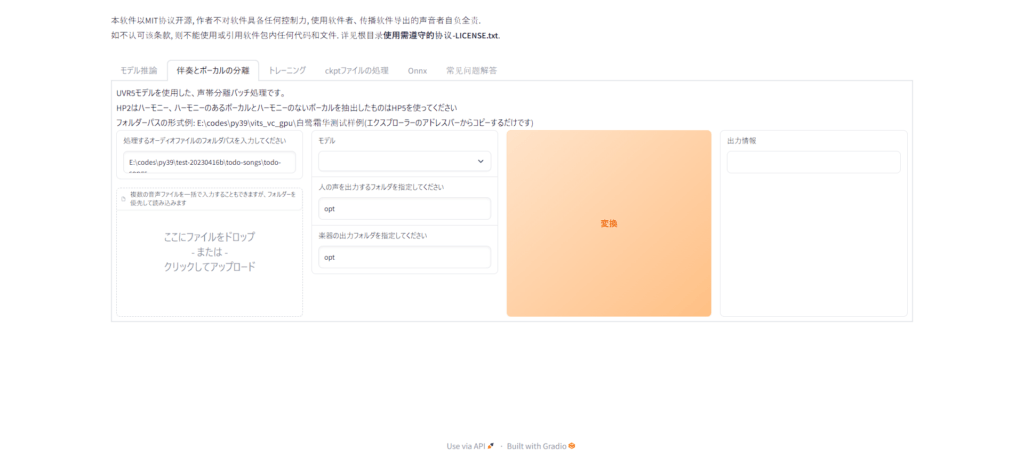
クリックしたらこのような画面が出てくると思います。
この画面で音楽から声と音を抽出していきます。
まず最初に「ここにファイルをドロップ- または -クリックしてアップロード」ここに歌わせる音源のデータをドラッグアンドドロップしてください
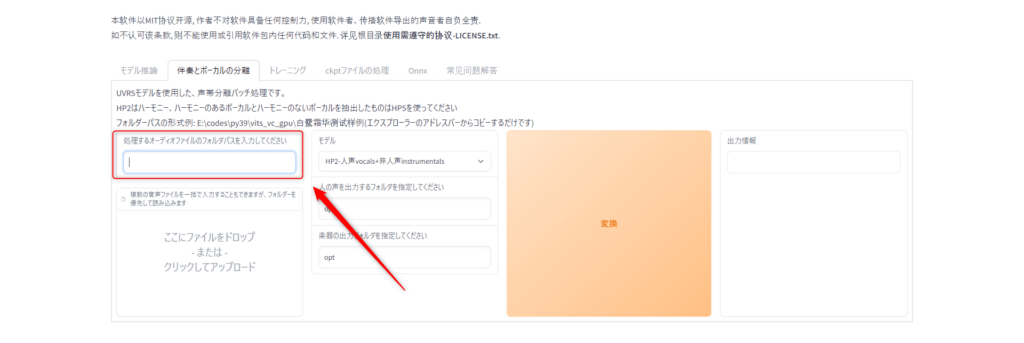
次に「処理するオーディオファイルのフォルダパスを入力してください」の欄にパスが書かれていると思うのですが削除してください。
削除しないと変換作業が動作しません。
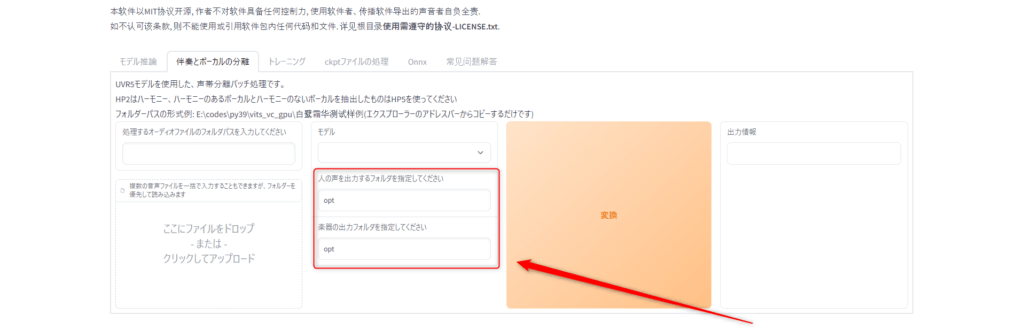
次に変換した音源を保存する場所を設定していきます。
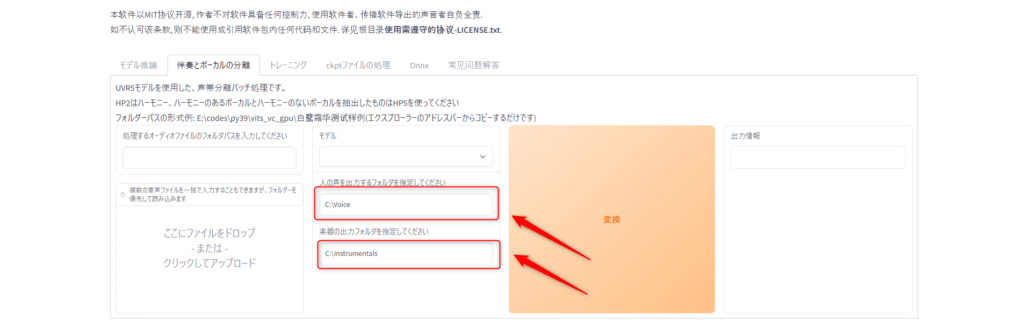
上記の「人の声を出力するフォルダを指定してください」に変換したとき声を保存するパスを設定します。
パスの設定方法は学習音声のダウンロードの下部分に取得方法が書いてるので保存したい場所にパスを設定してください。
次に「楽器の出力フォルダを指定してください」の部分にも保存したい場所のパスを入力しましょう。
今回自分はCドライブ直下で楽器の部分をInstrumentalsに声の部分をVoiceにしました。
なので自分の場合パスは
「C:\Instrumentals」
「C:\Voice」
になります。
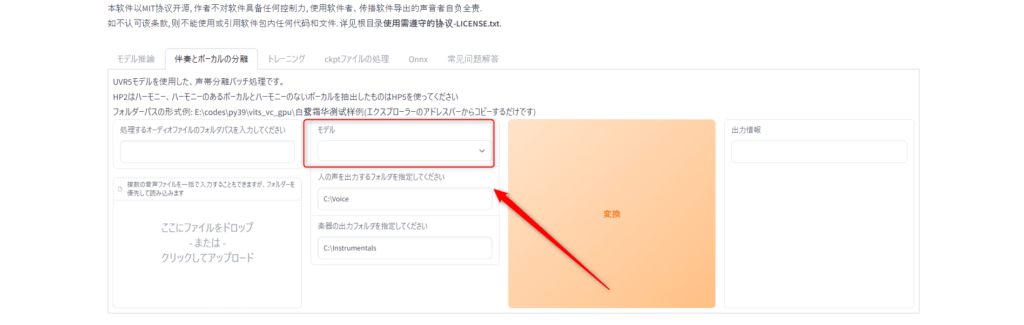
次に真ん中の欄のモデルを選択します。ここでは「HP2-人声vocals+非人声instrumentalsとHP5-主旋律人声vocals+其他instrumentals」があります。
「HP2-人声vocals+非人声instrumentals」は人の声と曲を分けます。
「HP5-主旋律人声vocals+其他instrumentals」は主旋律の声とハーモニーの声を分けます。
ここではハモリがあるかないかでする作が変わります。
ハモリとは何かという方は↓のリンクを見てください。
「https://www.youtube.com/watch?v=utwKvK1CNU4」
この工程が終わったらオレンジ色のボタン「変換」を押してください。
変換が終了したら先ほど指定したパスに声だけと楽器だけの音声が出力されます。
ハモリなしの場合この工程は終了です。
ハモリ有の場合は次の工程に進みます。(今回使用した楽曲はハモリがあるので次の工程に進んでください。)
ハモリ有の場合
ハモリがある場合は次にモデルの選択を「HP5-主旋律人声vocals+其他instrumentals」にしてください。
次に「ここにファイルをドロップ- または -クリックしてアップロード」のところに先ほど変換してできた声のファイル(人の声を出力するフォルダで出力された音源)をドラッグアンドドロップしてください。そしてもう一度変換を押してください。
そしたら楽器の出力先にハモリ、声の出力先に主旋律の声が声の出力先に入っているはずです。
これで音楽と声の出力は終了です。次に元の声から学習させた声で歌わせていきましょう!
変換方法
ここからはついに学習させたキャラに歌わせていきます!
開いたら上バーから「推論伴奏とボーカルの分離」をクリックしてください。
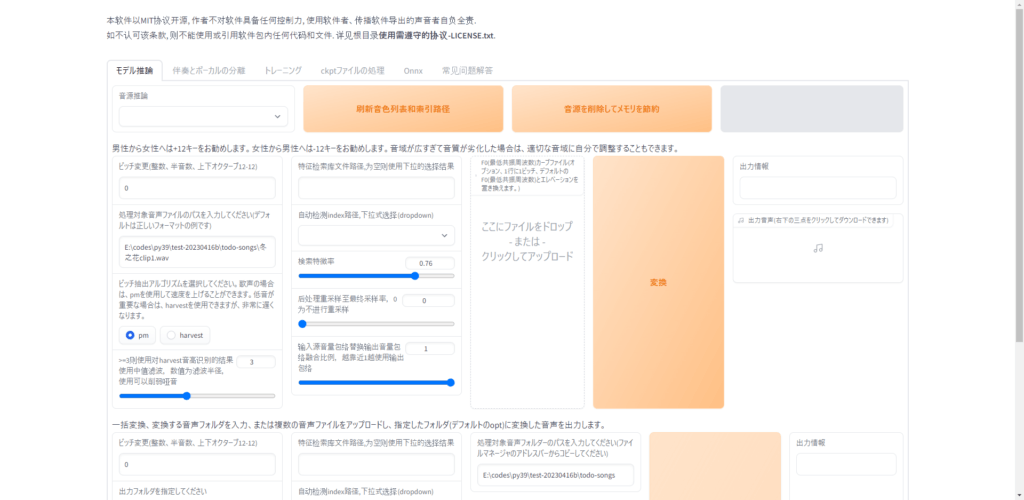
クリックしたらこの画面が出てくると思います。
今回この画面は細かい設定が多いので必要最低限の解説をさせていただきます。ご了承ください。
この画面で元音源からキャラクターに変換していきます。
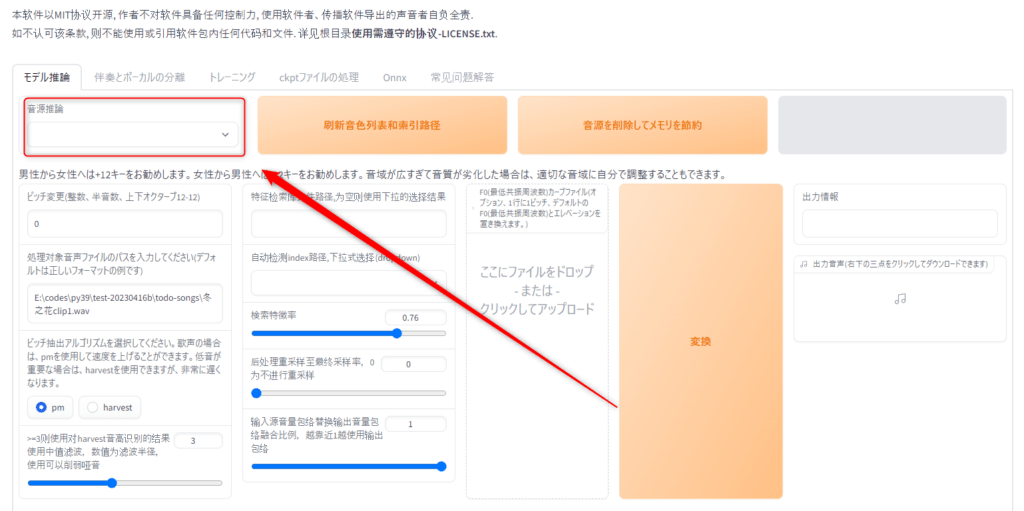
「音源推論」ここで学習させたモデルを読み込みます。
ここでは事前準備ステップ1で設定した名前があります(今回の例では「Zundamon」)があると思うので選択してください。
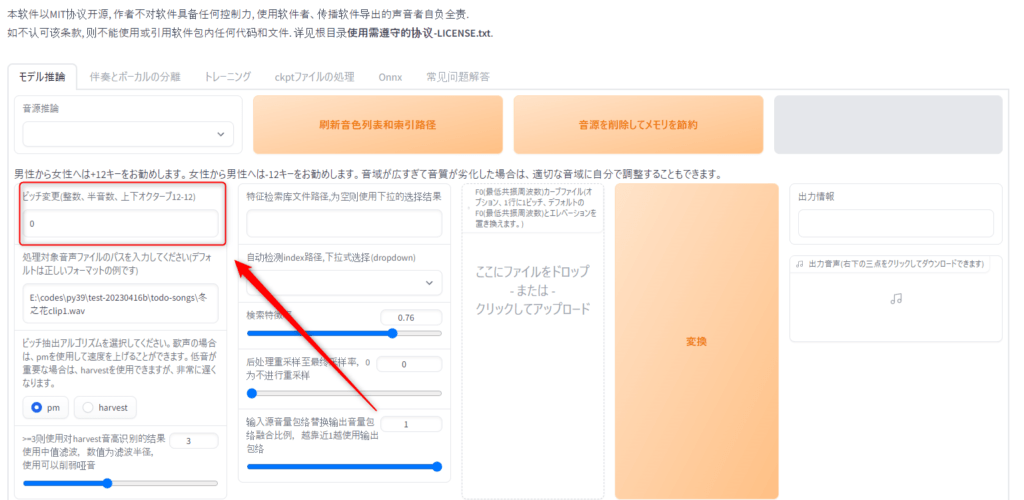
「ピッチ変更(整数、半音数、上下オクターブ12-12)」ここでは上に説明が書いてある通り「男性から女性へは+12キーをお勧めします。女性から男性へは-12キ」と書かれています。
個々では私が試した感じ大体初期値の0でokです。
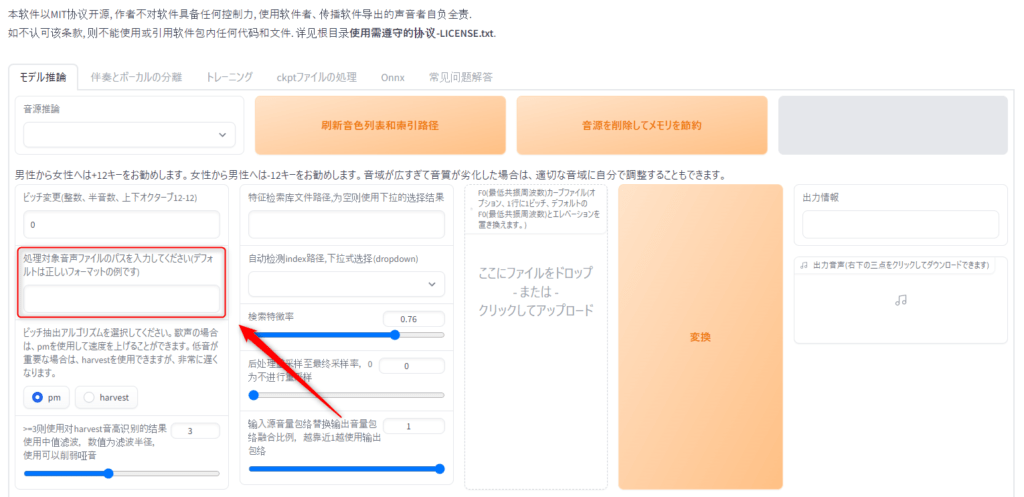
「処理対象音声ファイルのパスを入力してください(デフォルトは正しいフォーマットの例です)」ここでは読み込みをさせたい音源のパスを入力します。
ここでは音楽から声とそれ以外の抜き出しのところで変換した音源を指定してください。
ここの音源はハモリなしの場合はこの工程のみで大丈夫です。
ハモリ有の場合先ほど紹介した主旋律の声とハモリの音源を入れてください。
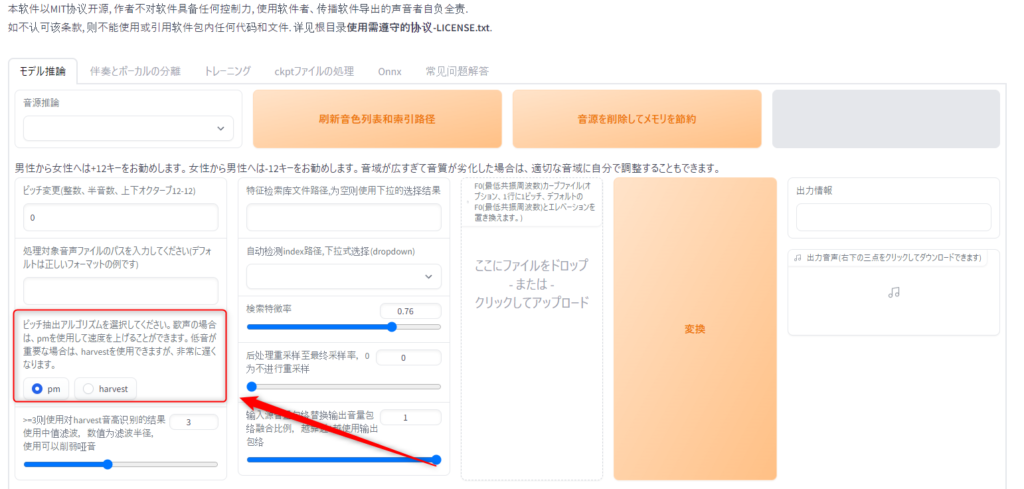
次にピッチ抽出アルゴリズムを選択していきます。
今回は歌声の場合なので初期値のpmでokです。
以下の手順が終了したら変換を押してください。
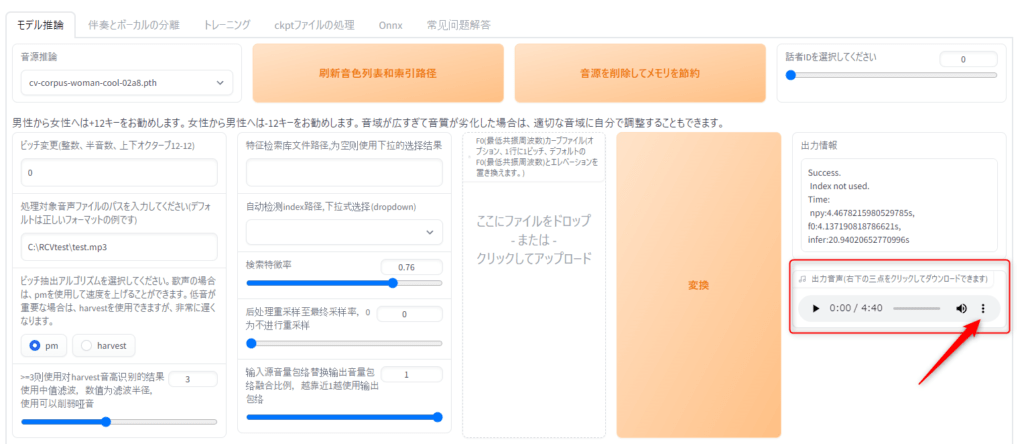
変換が終わると「出力音声(右下の三点をクリックしてダウンロードできます)」欄に色々出てくると思います。
この画面が出てきたら右下の3点をクリックするとダウンロードボタンが出てくると思うので。ダウンロードしてください。
この工程が終了したらハモリなしの場合カラオケ音源とボイス音源の2ファイル
ハモリ有の場合カラオケ音源と主旋律の声音源とハモリ音源の3ファイル
があると思います。
これで音源の準備は完了です。
ここから音声編集ソフトをインストールしてカラオケ音源と声音源を調整していきます。
音声調整
事前準備
今回は音声調整ソフトの「Audacity」を使用していきたいと思います。
以下のリンクをクリックしてください。
「https://www.audacityteam.org/」
リンクをクリックするとこのようなサイト画面が出てくると思うので、「DOWNLOAD AUDACITY」をクリックしてください。
クリックしてもらうとソフトがダウンロードされてインストーラーが立ち上がると思うので、流れに沿ってインストールしてください。
インストールが終了したらソフトを起動してください。
ソフトを起動したらこのような画面が現れると思います。
これでソフトの準備は完了です。
音源の調整
この画面の灰色の部分に先ほど作成したカラオケ音源と声音源をドラッグアンドドロップしてください。
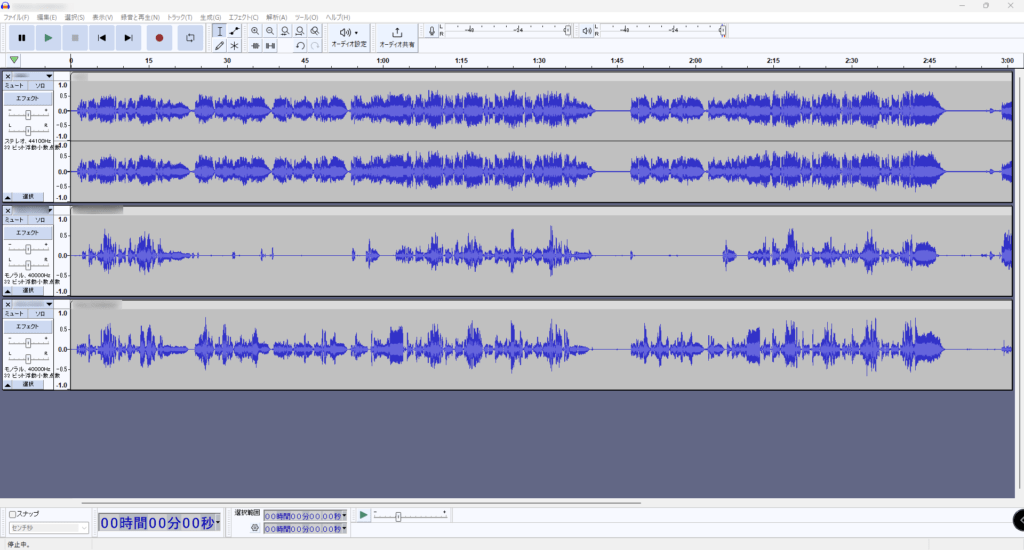
そしたらこのような画面が現れると思いますこの画面では各音源の波長が出ています。
一回上側の再生ボタンを押してみましょう。
再生ボタンを押してみて声とカラオケ音源がずれていない場合は次の工程を飛ばしてください。
音源データを調整する
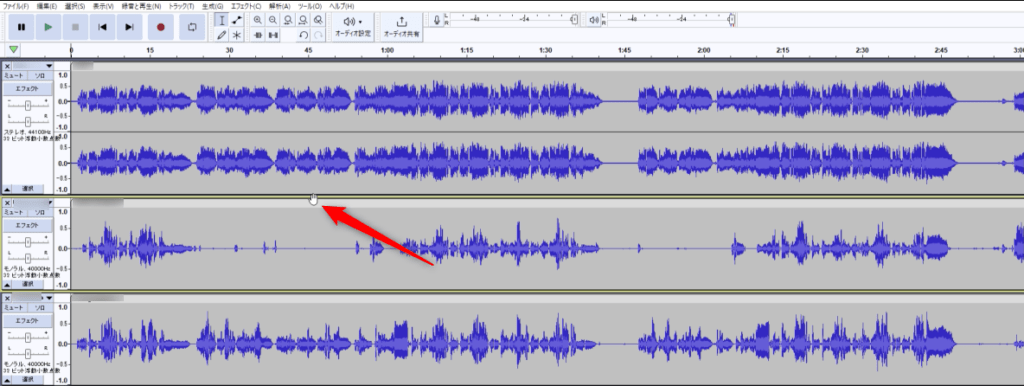
もしカラオケ音源と声がずれている場合どっちかの音声を調整しなければなりません。
音源波形の上側にカーソルを合わせると上記画像のようにカーソルがなるはずです、この時マウス左クリックをして左右に動かすと調整ができます。
ここでタイミングが合うように調整しましょう。
音量調整&エコーなど
次に音楽としてはこのままでも良いのですが、エコーや音量調整をするとさらに聞きやすくなると思うのでそこの調整をしていきましょう!
まず最初に音量の調整をしていきましょう。
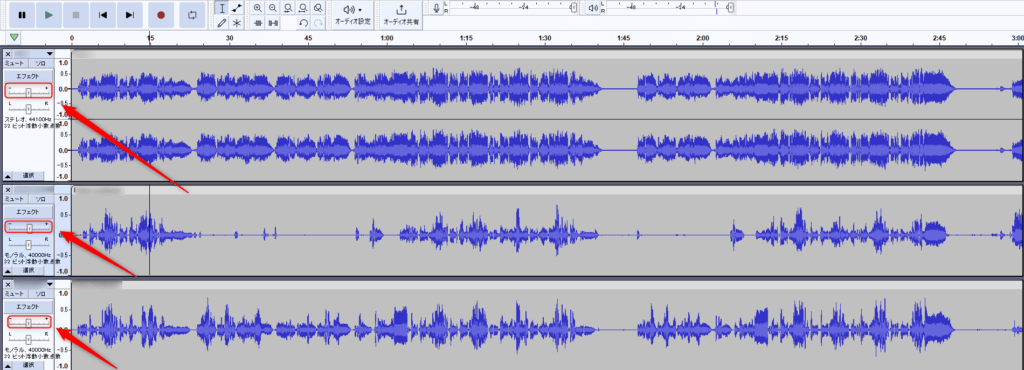
波形の左側に+-のバーがあると思います。この時再生ボタンを押して+-のバーを左右に動かして音量を調整します。
自分が今どの音をいじっているのかわからない場合はその上にある「ソロ」を押してもらうと現在調整している音源のみが流れます。
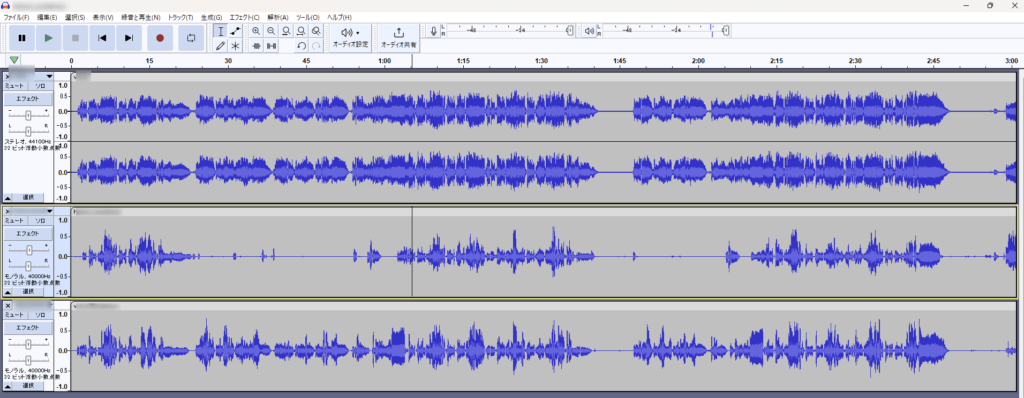
次に声にエコーをかけていきます。
エコーをかけたい音源の波形をクリックしてください。クリックすると周りが上記画像のように黄色枠で囲われると思います。囲われたら次に上のバーにあるエフェクトをクリックしてください。
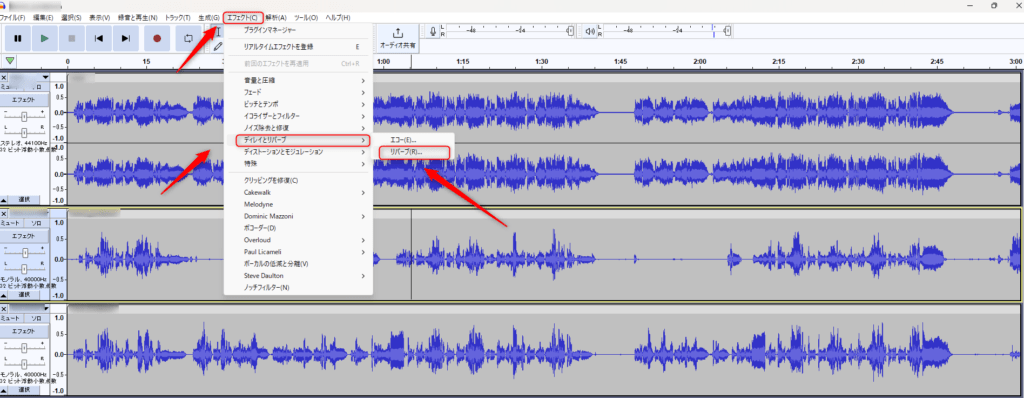
クリックするとディレイとリバーブという欄があるのでそこにカーソルを合わせてもらうとリバーブ(R)という欄があるのでそれをクリックしてください。
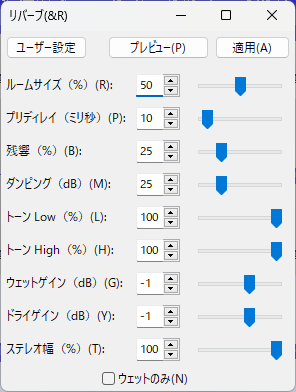
するとこのような画面になるので各数値をこのように設定してください。
数値を設定し終えたら右上の適用を押してください。
適用を押すと適用した声の音源が前よりも自然になっていると思います。
ハモリがある方はハモリの音源も同様に設定してください。
最後に
以上で歌わせる工程は終了です。
最後に歌わせた音源を保存していきましょう。
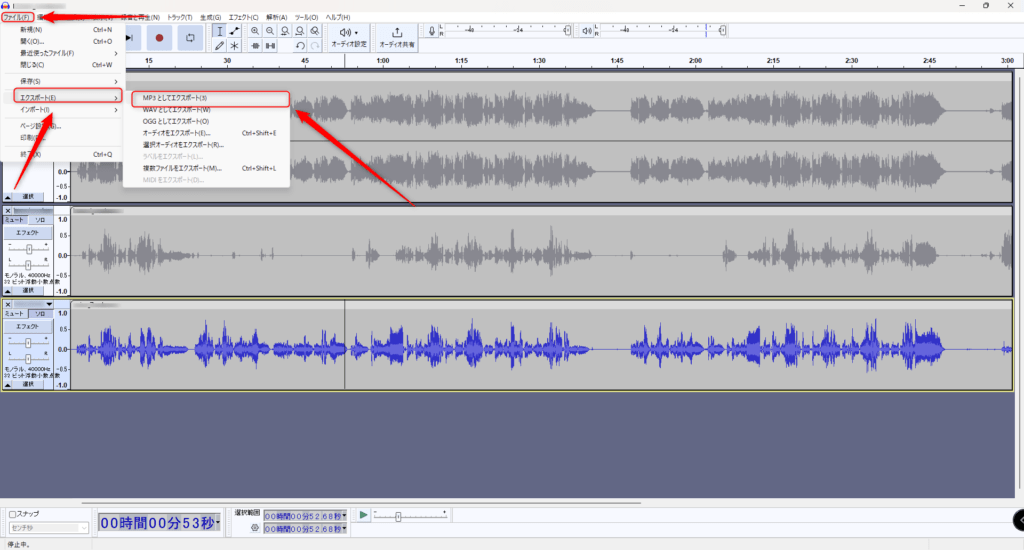
上のバーからファイルをクリックしてエクスポートにカーソルを合わせるとMP3としてエクスポートという欄があると思うのでそれをクリックしてください。そしたら以下のような画面が出てくると思います。
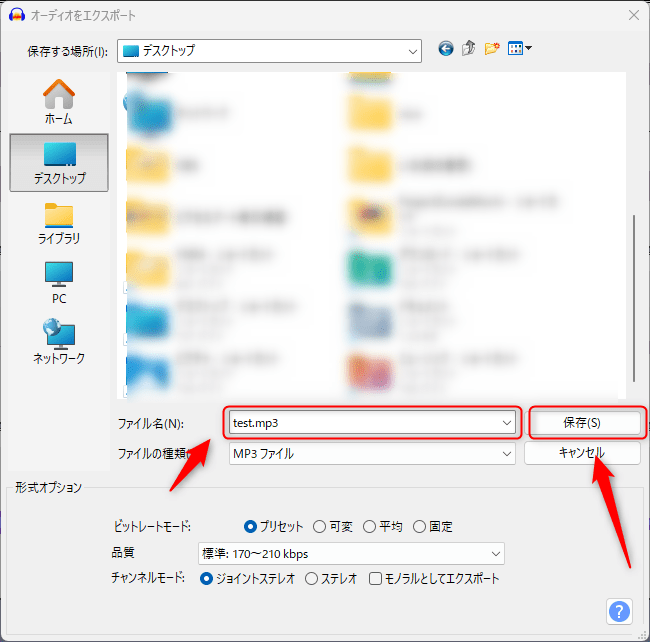
この画面が現れたら保存する場所を決定しファイル名のところに保存したい名前を設定して保存(S)をクリックしてくださいそしたら音源が保存されていると思います。
以上で好きなキャラに歌わせる方法の解説は終了です。お疲れさまでした。

